Sometimes papers are hard to read, because of their compact style. Explainable parts or discussions hardly find their way into the paper. I therefore decided to provide this ExpLiD-paper with some visual-based explanations, limitations and discussions to our paper.
ExpLiD-Version:
User Authentication via Multifaceted Mouse Movement and Outlier Exposure
Jennifer J. Matthiesen, Hanne Hastedt, Ulf Brefeld
In our paper, we cast the problem of user authentication based on their computer mouse trajectories as a unsupervised one-class problem incorporating additional data (outlier exposure) during the trainings process. The overall process can be separated into three parts: (i) Preprocessing, (ii) Training and testing of the model, (iii) Analysing characteristic features. We decided to investigate the mouse trajectory data as images, putting a focus on the shape rather then the direction of moving. We investigate different splitting methods, as well as different levels of information about the trajectory (views) such as pauses, clicks, and speed. To investigate the decision of the network and to visualise idiosyncratic parts of the mouse movement, we apply the layer-wise relevance propagation (LRP).

Have you ever thought about the movement of the mouse when you use a computer? While most of us uses the computer on a nearly daily bases, we rarely actively recognize the movement of the mouse cursor. We can think about them being similar to gestures in a inter human communication, where we also use pointing actions which are quite generally understood but execute on a really individual way. The same thing applies to the mouse cursor movement: they encompass general elements, like moving to certain objects, but its execution remains idiosyncratic.
User Authentication and Identification
Telling users apart can have two main objectives: User identification and user authentication. Detecting the right user in a set of all users is the task of user identification, which is usual done in a supervised multi-class classification setup. At this, all users are known a priori and part of the trainings data-set. In other words, when we get some yet unknown user sequence \(x\), we want to determined if it belongs to \(user 1, user 2, \dots, user \; n \).
In contrast, user authentication underlies a binary decision. We want to distinguish between the target user and all the remaining users. Note, that also here the common approach is likewise supervised, i.e. using data of both classes (in- and out-of-distribution data). The typical optimisation strategy uses a binary-cross entropy loss to increase the distance between the two entities (see Fig. 1c). When another dataset is incorporate in the latter strategy it is sometimes declared as unsupervised OE.
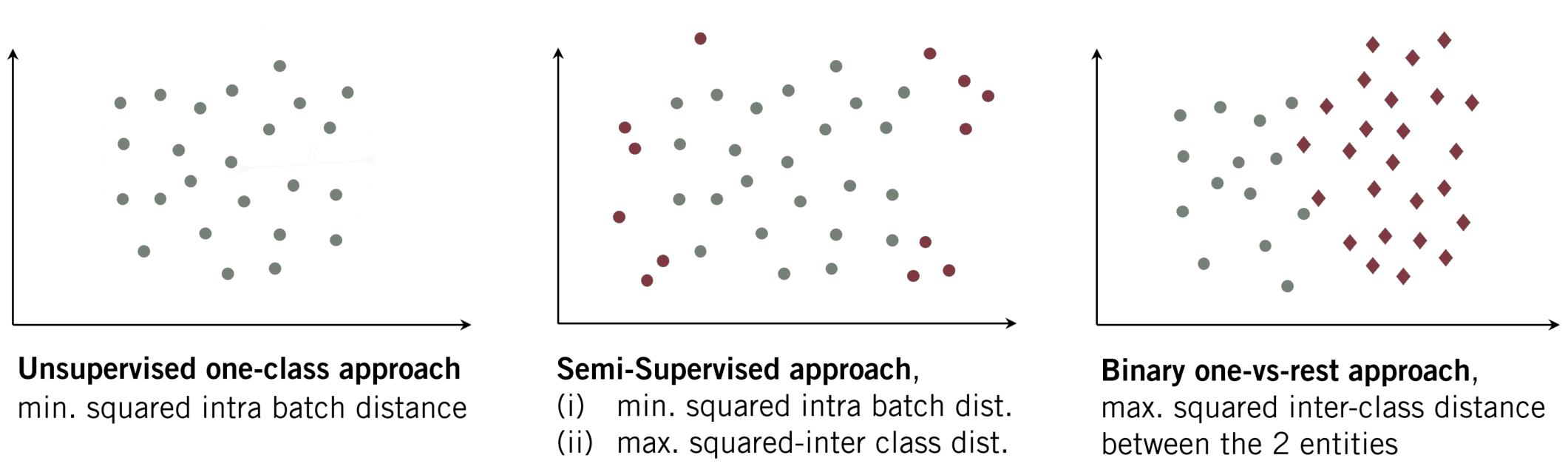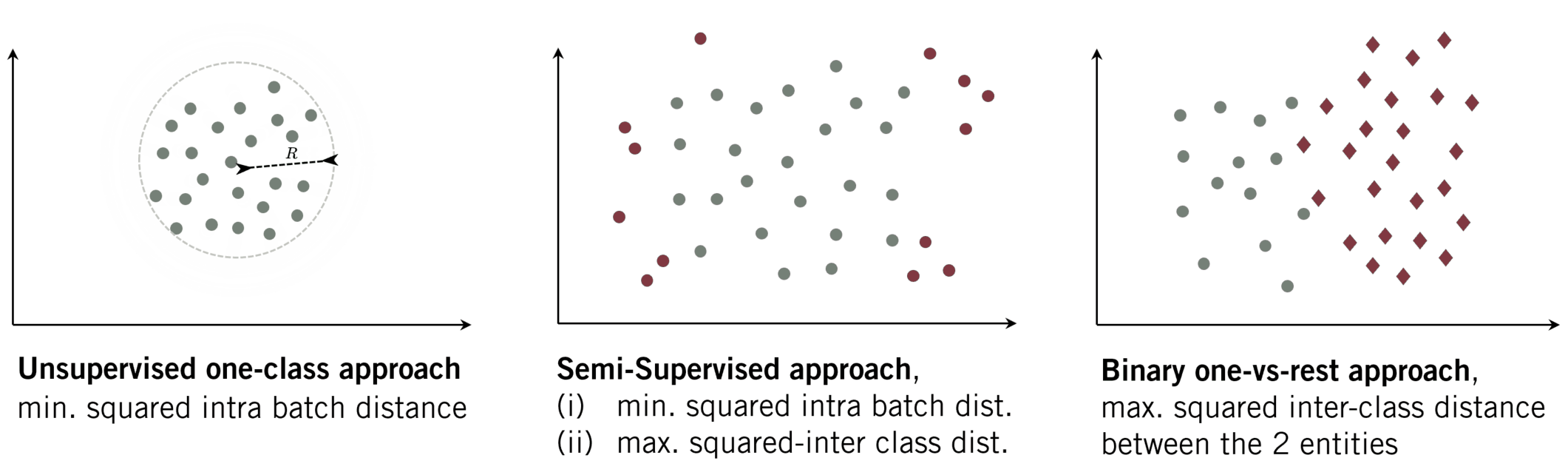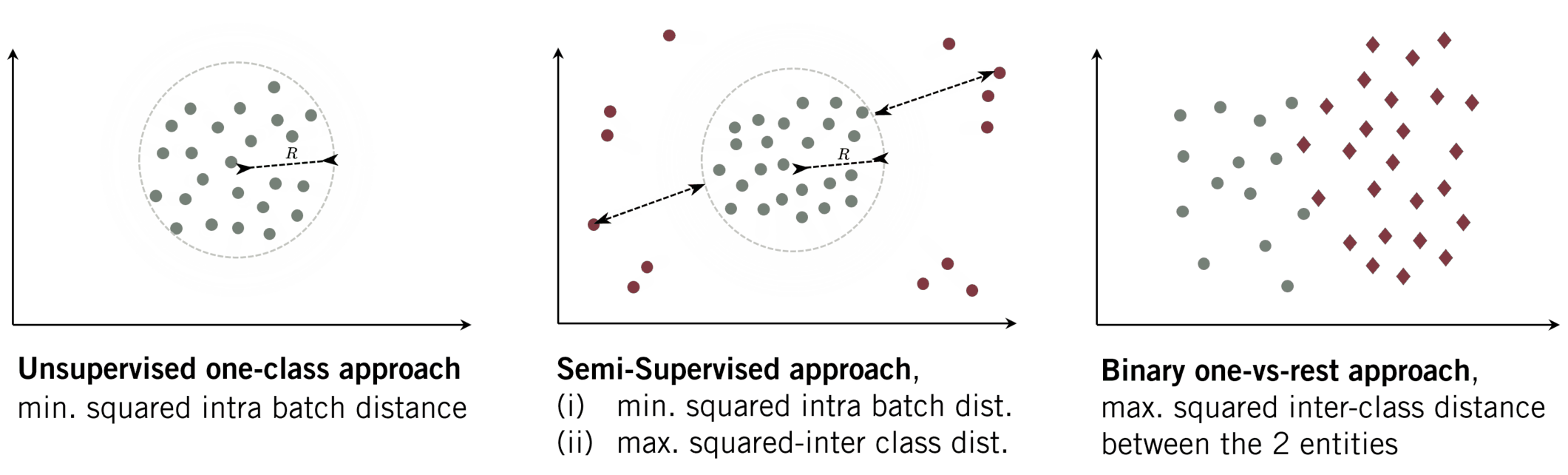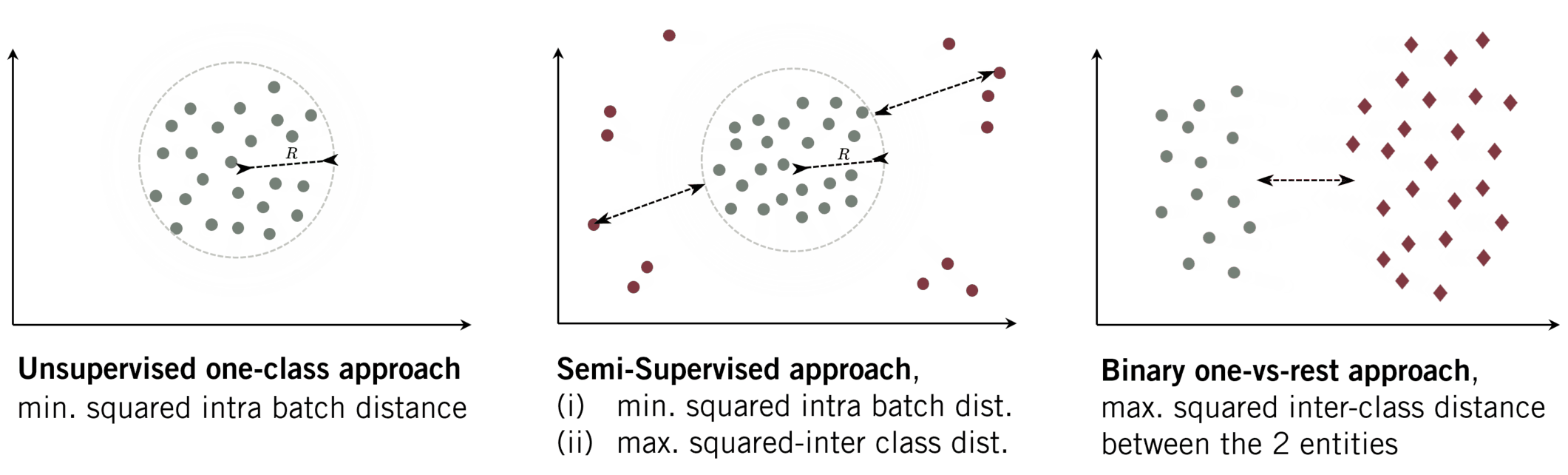
Anomaly Detection with Outlier Exposure
The idea of outlier exposure (OE) approach originates in the observation that, when learning a target concept, myriads of labelled examples exist that live in the same space but are known to not match the target concept (Hendrycks et al., 2019). While this insight borders on triviality, it is particularly powerful in unsupervised learning tasks like one-class and density estimation problems. Instead of only feeding observations of the desired target concept, additional data from possibly very different origins and sources is made available to the model that now faces contrastive tasks: Ultimately, the goal is to provide a minimal description of the desired target concept but additionally, there is a classification problem that needs to be solved simultaneously using only the auxiliary data.
When learning the features with a neural network for user authentication, we would like to design the features with two important characteristics.
- Compactness: As it is the goal of several one-class-based algorithms, the feature representation of data from the same class should be similar. Hence, a collection of extracted features of a given class will lie compactly in the latent space. We can reach such a representation when minimizing the inter-class distance while minimizing the radius \(r\) of the enclosing hypersphere.
- Descriptiveness: Besides a compact representation, the extracted images should likewise produce distinct representations. For natural images these are e.g. edges. We want to learn what is descriptive for mouse trajectories in general. Learning such a descriptive representations is likewise a desired characteristic in multi-class classification, where those features extractions ensure a large inter-class distance.
Optimizing only wrt. minimizing the radius \(r\)of the hypersphere will directly result in the hypersphere collapse (Chong et al., 2020) where all data is mapped to the same point. Usually, further constraints (e.g. a slack variable) are included. We observed that training the network simultaneously with both objectives (descriptiveness and compactness) can counterbalance such a hypersphere collapse.
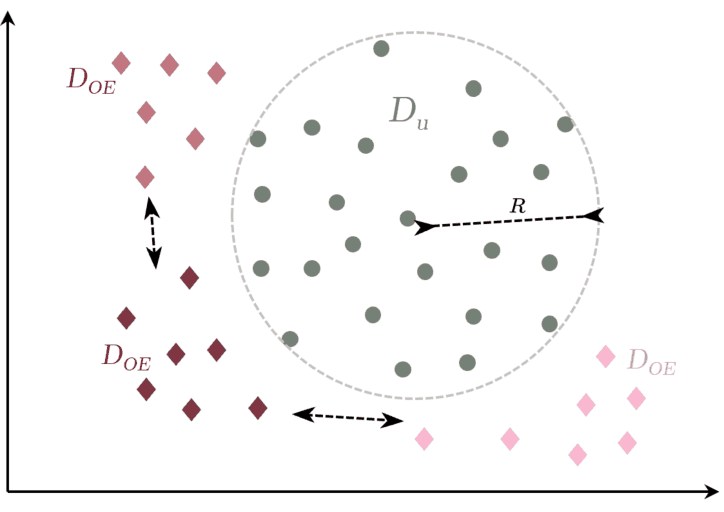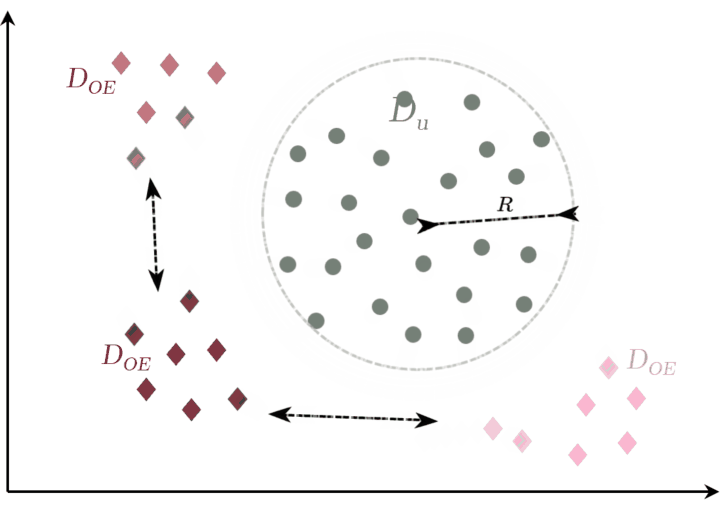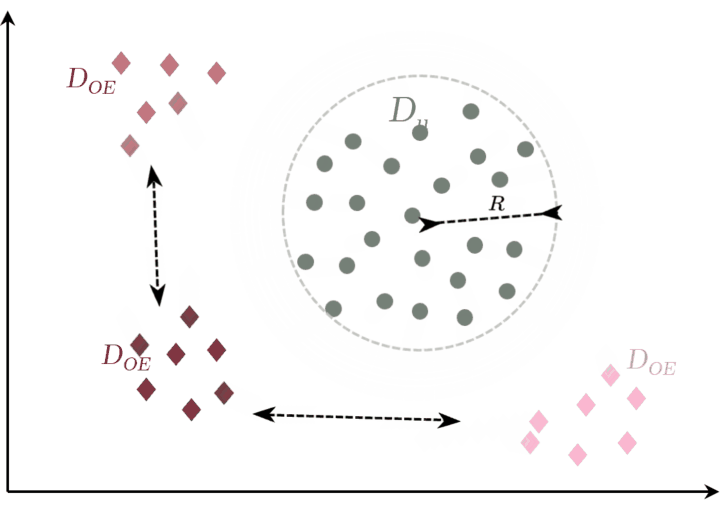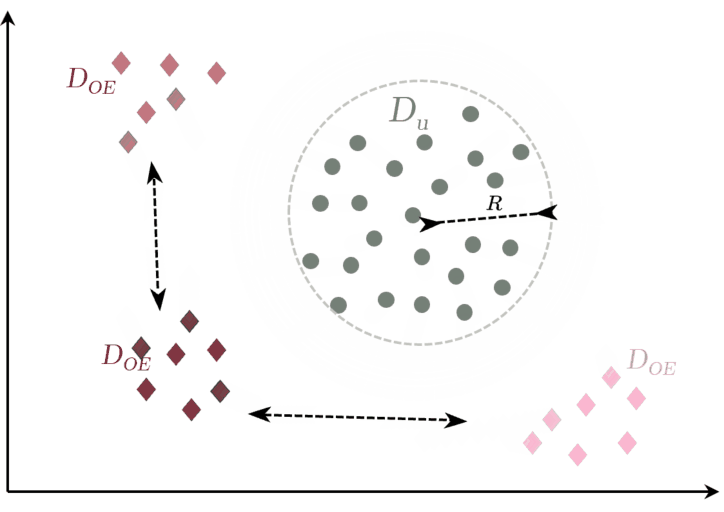
Fig. 2: OE-based approach (Perera et al. (2019))
(i) min. squared intra batch dist.
(ii) max. inter squared dist. between classes (DOE).
Terminology : from unsupervised to supervised OE
When I started reading into the topic of anomaly detection, I stumbled upon quite some ambiguous terminologies. As in many areas, also in AD there is no overall consents how to name different setups. Despite some outliers, the most paper seem to agree with the following namings:

Representing Mouse Trajectories
Not every mouse tracking provides equally spaced time steps, since some record mouse dynamics just on moving the cursor. If this is the case, the time gaps (pauses) between the single movements can provide valuable information. For example, a pause before a click can give insights into the cognition capacity and the processing time of the user, since such a pattern of hesitation (sClickTale) occur more often during a task with a higher level of difficulty (Ferreira et al., 2010). In data which is recorded in regular time steps, this information is represented by a repetition of the same coordinate. Therefore pauses can be highly diagnostic since they reflect the cognitive capacity of the user during the interaction with the computational device Analysing data with non-equal time steps using sequential methods may lead to neglecting the information of pauses.
Most mouse data records are disjoint from any information about the user and the underlying user interface (UI) (Balabit, TWOS). However, mouse movements are highly influenced by the underlying UI. They consist likewise of movements for interacting with the application as well as idiosyncratic movements, which are most valuable to retrieve information about the user. Since the UI is often not known a priori, we need to identify users regardless of the underlying interface. In our paper, we aim at devising a representation that is as independent as possible from actual UI's and rather aim at capturing how a user moves the pointer to a certain location instead of where exactly an action has been performed. While related work decided to do this via a first-order representations and derivatives \(dx/dt \) and \(dy/dt\) (Antal et al., 2020), we tried to shift the focus on the shape of the trajectory plotting them as images. In this way certain patterns (e.g. loops) can be detected.
Trajectory as images
We extract multiple information from the mouse trajectories: speed, clicks and pauses. For each view, we plot a separate image. Different views of the same sub-trajectory serve later as a multo-channel input to the network during training. For a better comparison, we decided to leave the number of channels unchanged. When testing with one view, the channels are used for a representation in rgb. For two views, we double one of them, to still fill the requirement of the input shape for the network.
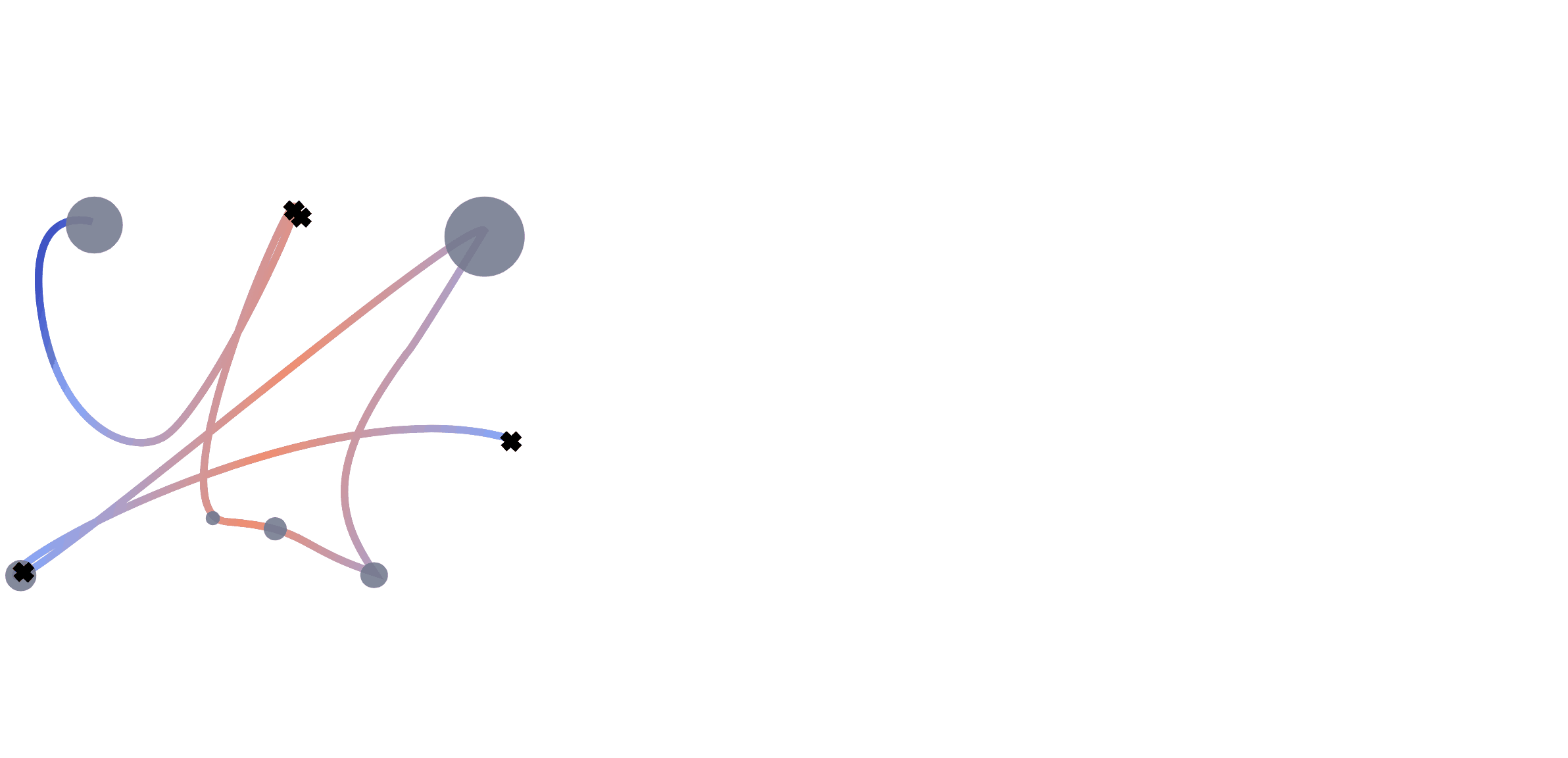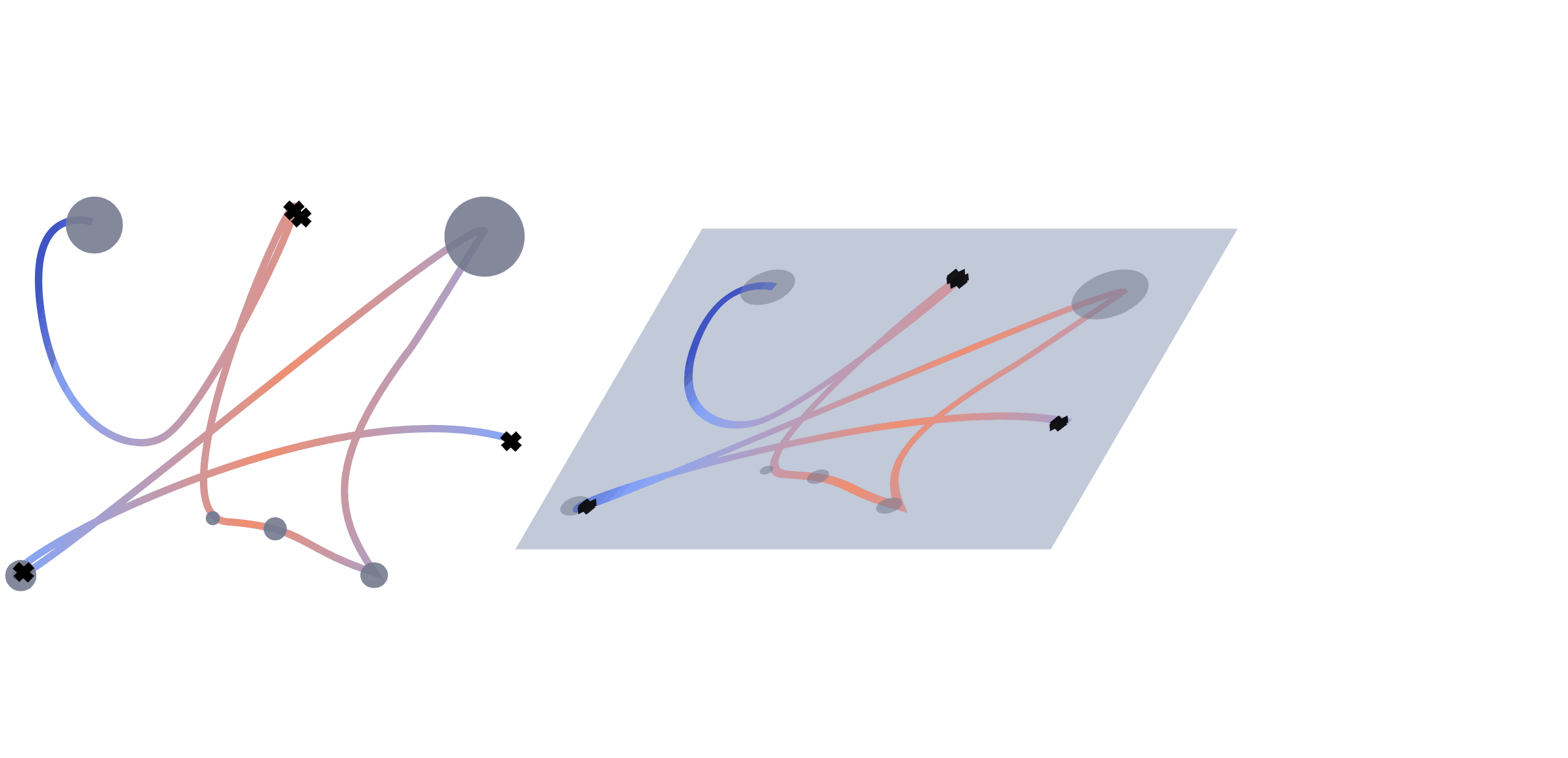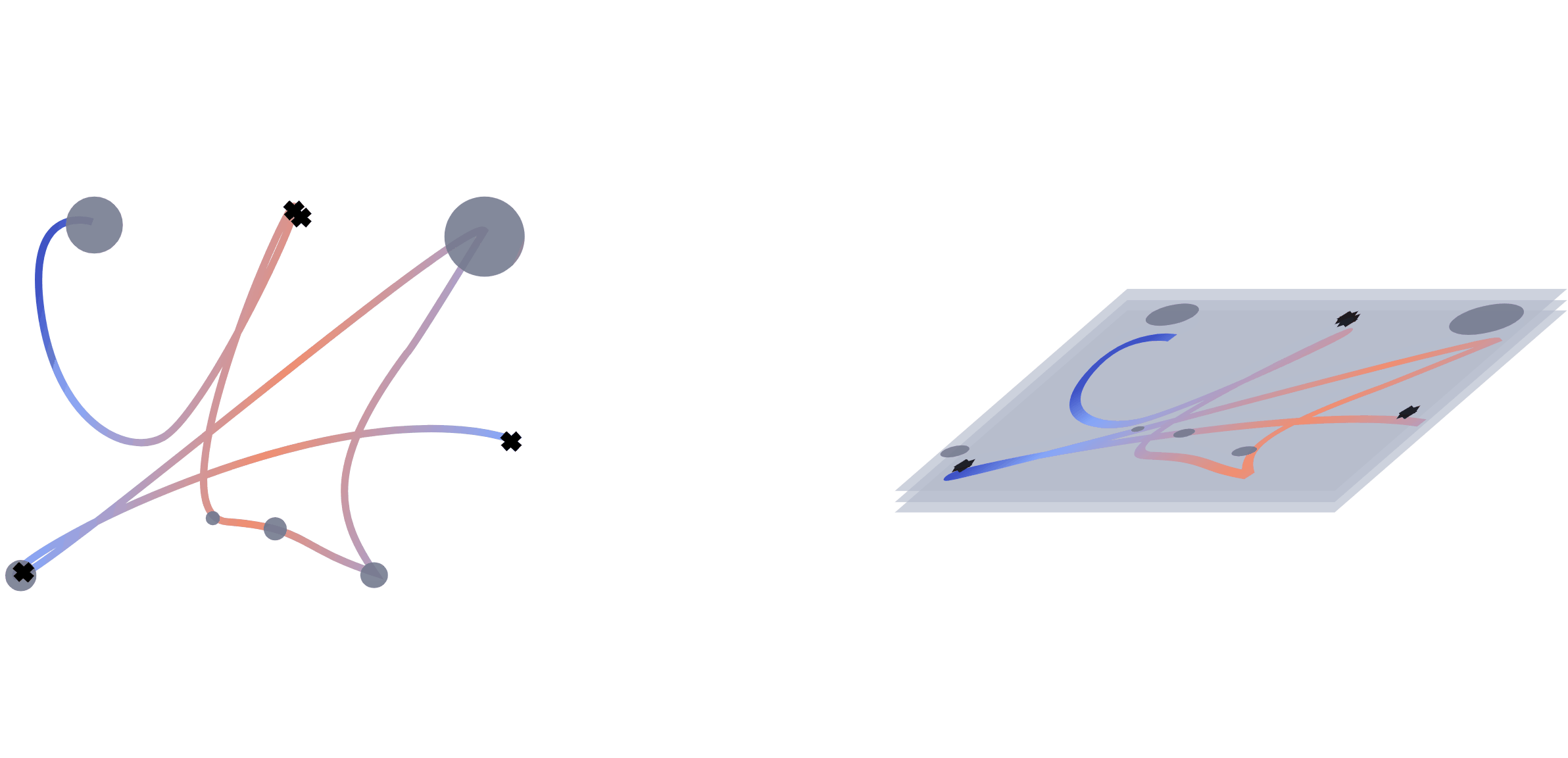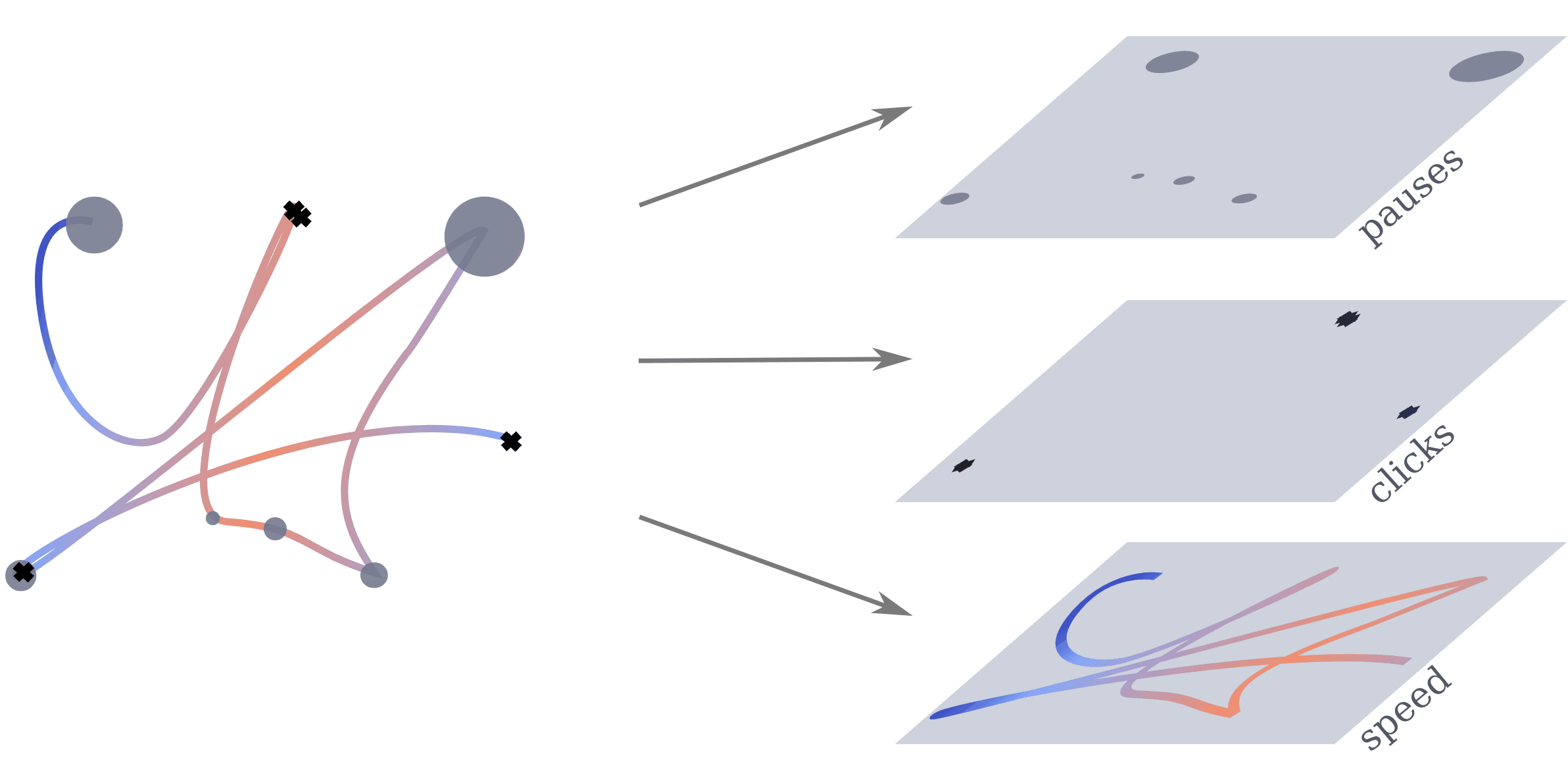
For the trajectory view, subsequences of the trajectory are re-scaled, plotted and save as images. We adapt the size of the plot to the range of the respective trajectory to assure no bias from the positioning on the screen. To maintain the temporal information, we encode the speed of the movement with a colour interval, where the colour is determined by the actual speed of movement \(s_t\) at that position. To encode the speed value, we test two different normalisation approaches. Both ground on the speed \(s_t = \frac{d_{t}}{\tau_t}\) of the movement , where \(d = \sqrt{(x_{t}-x_{t-1})^2 +(y_{t}-y_{t-1})^2}\) is the covered distance, but are normalized (i) by the average speed: \begin{equation*} s_t^{(avg)} = \frac{s_t}{\frac{1}{T}\sum_{t=1}^{T}\frac{d_t}{\tau_t}} \end{equation*} and (ii) with a log-variant with \(\tilde s_t= \log (1+s_t)\) \begin{equation*} s^{(log)}_t = \frac{\tilde s_t - \tilde s_{\max}}{\tilde s_{\max} - \tilde s_{\min}}, \end{equation*} respectively, where \(\tilde s_{max}=\max_t \log (1+s_t)\) and \(\tilde s_{min}\) analogously.
A click view is simply containing indicators at click positions which are visualized by black crosses in the image.
The pause view contains the length of the pauses at the observed positions and is visualized by circles with radii corresponding to the length of the pause. We scale every pause \(p\) so that the radius of the smallest pauses starts at a radius of 50px. The upper limit in size was set to a radius of 200px for the longest pauses. Mouse actions were recorded with 60fps resulting in a minimum distance of 16 milliseconds between data points. Therefore we set the threshold for pauses to 0.02 seconds. We discard these data points during scrolls, since they cause the coordinates to be zero.
The Influence of the Interface on Mouse Trajectories
The underlying UI has a significant influence on mouse movement and can be of huge variety. Likewise, one does often not have information on the pointing device or the operating system at hand. Both are proven to be influential on the cursor movement and the way how data is recorded (Gross et al., 2015). In this work, we propose an approach which tries to be unaffected by such influences by normalising and standardising the sub-trajectories. We did not include additional data augmentation to generate more data (e.g through mirroring or rotation), since mouse trajectories are not necessarily translation invariant. While some movements, like patterns of confidence (e.g. straight and direct movements), can still be detected in mirrored or rotated images, other mouse movement motifs might not be orientation invariant or might lose their idiosyncratic characteristic.
Splitting the trajectory
A whole sessions of mouse data encompasses a long time in the Balabit dataset
(from 1 hour, 43 minutes and 37 seconds (user 29) to 2 hours, 4 minutes and 35 seconds (user 7)).
Therefore we split the session into smaller sub trajectories.
Since in the Balabit and the
TWOS dataset mouse data is just recorded when the cursor moves,
the a splitting after a fixed amount of time and after a fixed amount of data points do not result in the same splitting.
We investigate three different splitting methods and show examples of the first 5 images of each user
(![]() not cherry picked)
below.
not cherry picked)
below.
Time Difference Split (TD) (Chong et al., 2020) splits a sequence when the time difference between two consecutive mouse operations (movement or click) exceeds a predefined threshold \(\rho \in \{1s, 60s\}\). Since this may result in very short sub-trajectories, we only split if the resulting sub-sequences contain at least 100 data points.










Equal Length Split (EL) (Matthiesen et al., 2020) splits the data into sub-sequences of the same length of data points, \(\omega \in \{200, 1000\}\), irrespective of occurring events or movements. The last sequence is naturally shorter and usually discarded. In contrast to the TD method, the resulting sequences have the same length. Note that the identical number of data points does not result in the same amount of coloured pixels in the generated image.










Equal Time Splitting (ET) is a temporal analogy to the previous splitting criterion and splits the trajectory after a fixed amount of time. We experiment with the thresholds \(\upsilon \in \{10s, 120s\}\). Since the used mouse data is not recorded using equal time stamps but rather recorded on movements, this splitting method will not result in equally sized sub-sequences. Although this extension is straightforward, there does not seem to exist related work on this method.










Visualisation of important information of the mouse dynamics
We utilise the layer-wise relevance propagation (LRP) (Bach et al., 2015) to investigate which parts of the input lead to creating compact and descriptive features for each user. In addition, we implement the \(z^+\)-rule and a relevance filter as suggested in (Fabi., 2021). We adapt the threshold value for the filter to \(k= 0.05\). The results of the first four images of user 7, 20, 12, 15 of the test set (not the same as shown above) using the EL1000 split are shown in Figure 8. We chose to investigate user 12 and 15 as the worse and best performing ones. User 7 and 20 were picked since those gave better results with hand-crafted features (again, the best and worse performing of those users), which we considered interesting. In contrast to the paper, we did not recolor the trajectories. Each view is represented in one color.




The LRP visualisations show that pauses seem to be relevant. Clicks in general do not seem to be of high relevance for most of the users, unless they overlap with pauses. However, for user 20 clicks clicks seem to be more important. In the work of Chong et al. (2020) only the trajectory information was plotted and used as input for a CNN. Using a pre-trained CNN, they show that the edges are the relevant element for the decision process of the network. Incorporating multiple layers of information such as pauses and clicks, revealed that pauses seem to carry an idiosyncratic factor of the computer mouse interaction.
Our observations are based on the created images. We did not investigate different ways of plotting pauses. Therefore we can not exclude a potential impact of the plotting method.
Things to work on
To reach our results, we used 1000 data points. In Balabit this translates to 5.5 minutes in an average of mouse dynamics data. However, using 200 data points, which translates to approximately 1 minute, we reach likewise a good performance. Both are still quite long and we are not there yet! While related approaches manage to authenticate users in less time, they often follow a fully supervised approach and solving therewith the wrong problem. Others might rely on hand-crafted features, which do not work for the users from Balabit as shown by (Matthiesen et al., 2020) or using a controlled environment.
We scaled the sub trajectories to fill the generated image, so that we would exclude any bias of the used area on the screen (we do not want to identify the user based on their screen). However, even smaller parts of the trajectory are enlarged by this. As later results (Neagelin et al. 2023) showed, the length of the movements can change under certain conditions (e.g. perceived stress). Normalising the size might therefore reduce too much information.
Citation of the paper
Cited as:
Matthiesen, J.J., Hastedt, H., Brefeld, U. (2023). User Authentication via Multifaceted Mouse Movements and Outlier Exposure. In: Crémilleux, B., Hess, S., Nijssen, S. (eds) Advances in Intelligent Data Analysis XXI. IDA 2023. Lecture Notes in Computer Science, vol 13876. Springer
Or
@InProceedings{Matthiesen2023UserAuthentication,
title = "User Authentication via Multifaceted Mouse Movements and Outlier Exposure",
author = "Matthiesen, Jennifer J. and Hastedt, Hanne and Brefeld, Ulf",
editor = "Cr{\'e}milleux, Bruno and Hess, Sibylle and Nijssen, Siegfried",
booktitle = "Advances in Intelligent Data Analysis XXI",
year = "2023",
publisher = "Springer Nature Switzerland",
address = "Cham",
pages = "300-313",
isbn = "978-3-031-30047-9",
}
References
[1] Dan Hendrycks, Mantas Mazeika, and Thomas Dietterich. 2019. Deep Anomaly Detection with Outlier Exposure. In International Conference on Learning Representations.
[2] Penny Chong, Lukas Ruff, Marius Kloft, and Alexander Binder. 2020. Simple and Effective Prevention of Mode Collapse in Deep One-Class Classification. CoRR abs/2001.08873 (2020). arXiv:2001.08873 https://arxiv.org/abs/2001.08873
[3] S. Ferreira, E. Arroyo, R. Tarrago, and J. Blat. 2010. Applying mouse tracking to investigate patterns of mouse movements in web forms. Ph. D. Dissertation. Universitat Pompeu Fabra.
[4] A. Fülöp, L. Kov´acs, T. Kurics, and E. Windhager-Pokol. 2016. Balabit Mouse Dynamics Challenge data set. https: //github.com/balabit/Mouse-Dynamics-Challenge
[5] Margit Antal and Norbert Fej´er. 2020. Mouse dynamics based user recognition using deep learning. Acta Universitatis Sapientiae, Informatica 12 (07 2020), 39–50. https://doi.org/10.2478/ausi-2020-0003
[6] Shawn C. Gross and John V. Monaco. 2015. Handling Artificial Acceleration in Mouse Movement Biometrics
[7] Athul Harilal, Flavio Toffalini, John Castellanos, Juan Guarnizo, Ivan Homoliak, and Mart´ın Ochoa. 2017. TWOS: A Dataset of Malicious Insider Threat Behavior Based on a Gamified Competition. In Proc. of the International Workshop on Managing Insider Security Threats (Dallas, Texas, USA) (MIST ’17). Association for Computing Machinery, New York, NY, USA, 45–56. https://doi.org/10.1145/3139923.3139929
[8] P. Chong, Y. Elovici, and A. Binder. 2020. User Authentication Based on Mouse Dynamics Using Deep Neural Networks: A Comprehensive Study. In IEEE Transactions on Information Forensics and Security, Vol. 15. 1086–1101.
[9] Jennifer J. Matthiesen and Ulf Brefeld. 2020. Assessing User Behavior by Mouse Movements. In HCI International 2020 - Posters, Constantine Stephanidis and Margherita Antona (Eds.). Springer International Publishing, Cham, 68–75.
[10] Sebastian Bach, Alexander Binder, Gr´egoire Montavon, Frederick Klauschen, Klaus-Robert M¨uller, and Wojciech Samek. 2015. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLOS ONE 10, 7 (07 2015), 1–46. https://doi.org/10.1371/journal.pone.0130140
[11] Kai Fabi. 2021. Layer-wise Relevance Propagation for PyTorch. https://github.com/KaiFabi/PyTorchRelevancePropagation.
[12] Naegelin, M., Weibel, R.P., Kerr, J.I., Schinazi, V.R., La Marca, R., von Wangenheim, F., Hoelscher, C., Ferrario, A.: An interpretable machine learning approach to multimodal stress detection in a simulated office environment. Journal of Biomedical Informatics 139, 104299 (2023). https://doi.org/https://doi.org/10.1016/j.jbi.2023.104299,