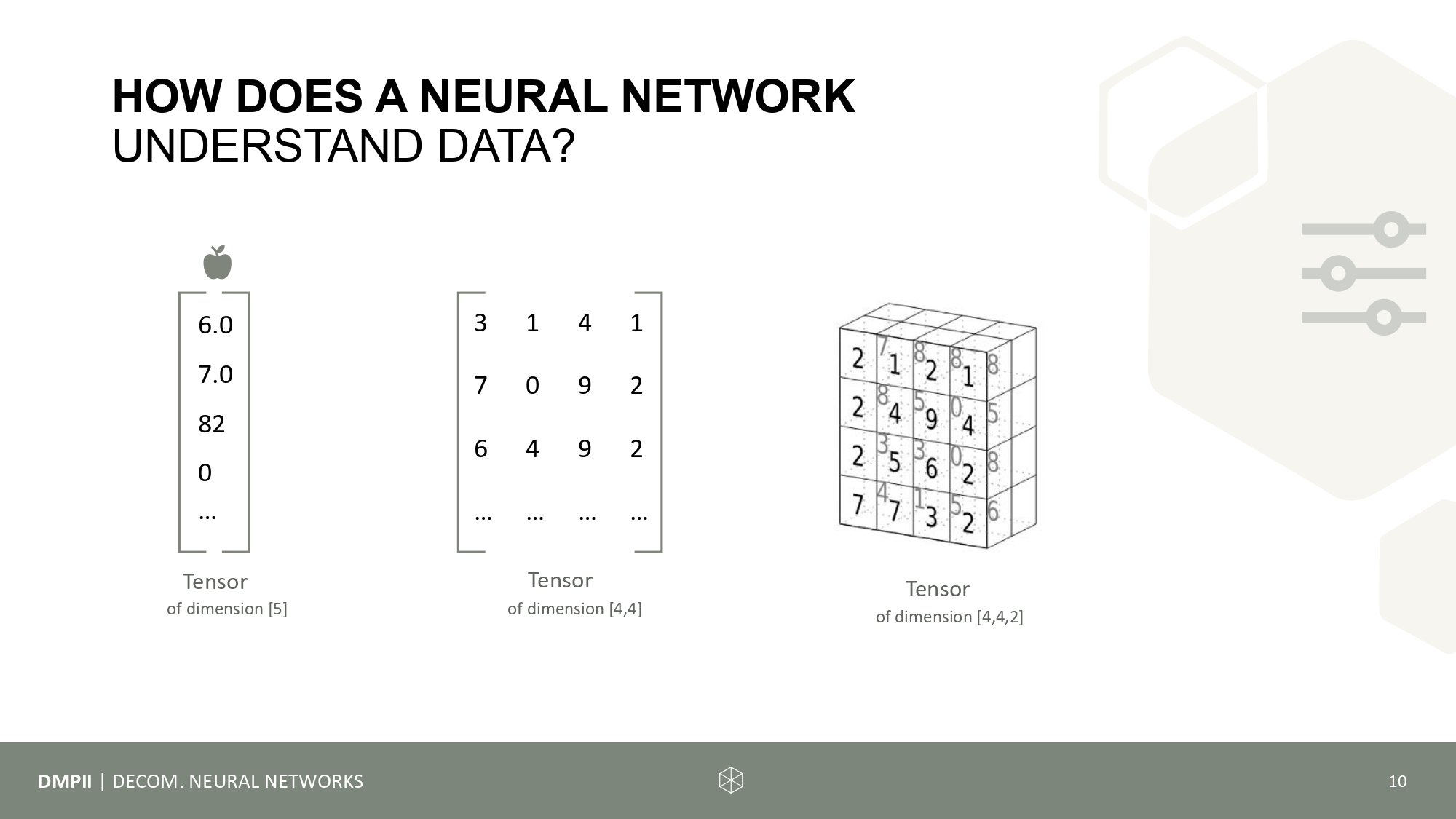
The main topic of the third session is bias in data and the different forms of bias, e.g. group attribute bias, overgeneralization bias, or selection bias. Together, we will develop methods for create representative samples, with and without pre-knowledge using the fictive example of an infinite amount of gummi bears (without discriminating the green ones). Further this session will introduce you to representational formats of data, namely vectors, matrices, and tensors.
We will train our own network to classify cats and dogs using python, pytorch and torchvision. A step-by-step visualization will help you gaining more understanding of the theoretical functionality of a convolutional neural network.
In this session, we will finally start with some hands-on coding! We recommend a device with at least 8GB of RAM for it (preferably a laptop over a tablet). Please prepare your python environment and your IDE for this session. We recommend PyCharm.
-
Download the code from
https://github.com/jjmatthiesen/DecomNN_lecture. You can either download as a zip folder or clone it via the terminal (recommended). - Read the README.md and follow the steps. Make sure that you have set up the /data folder as declared
- run the load_test.py to check if everything is correct.




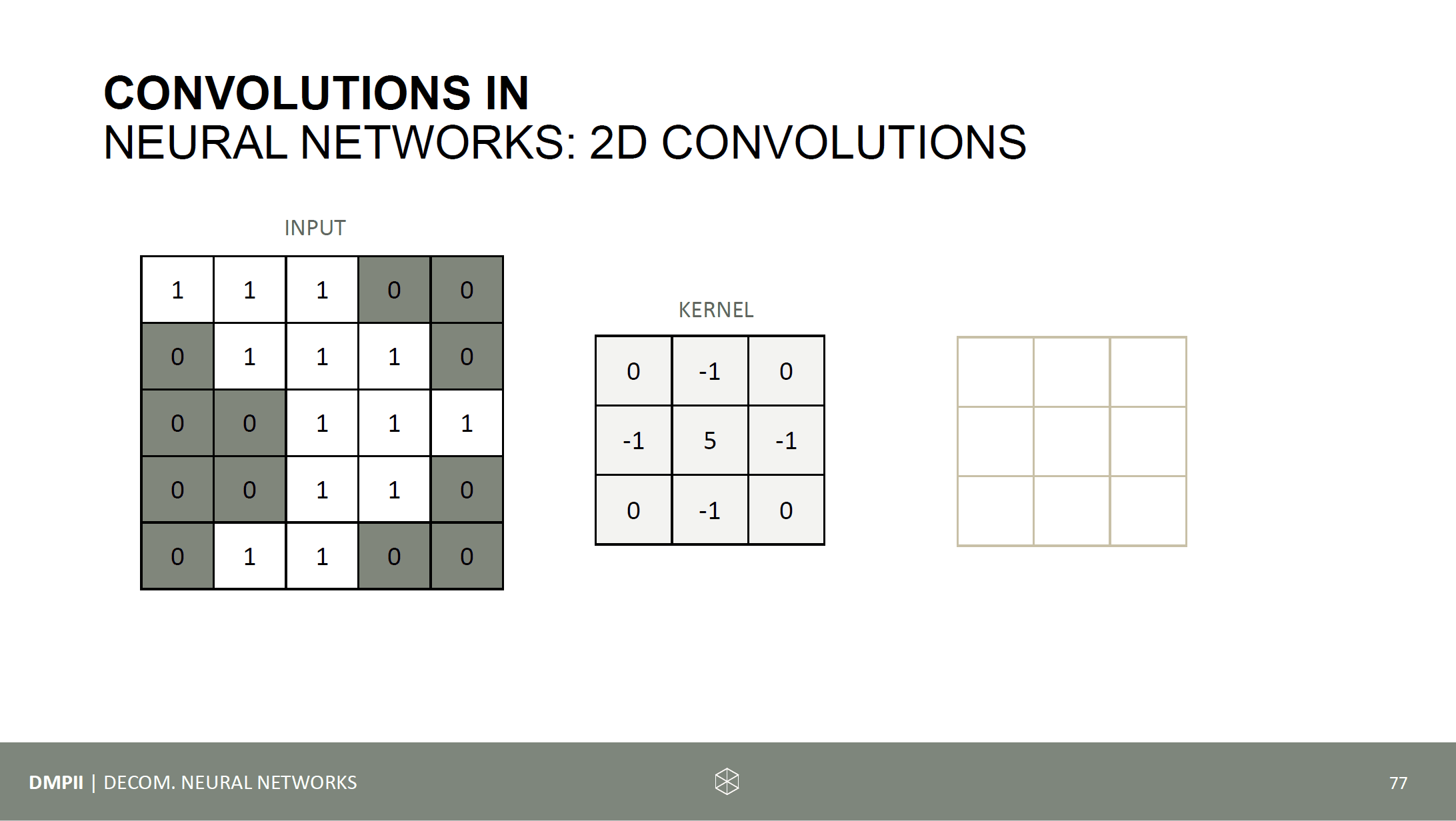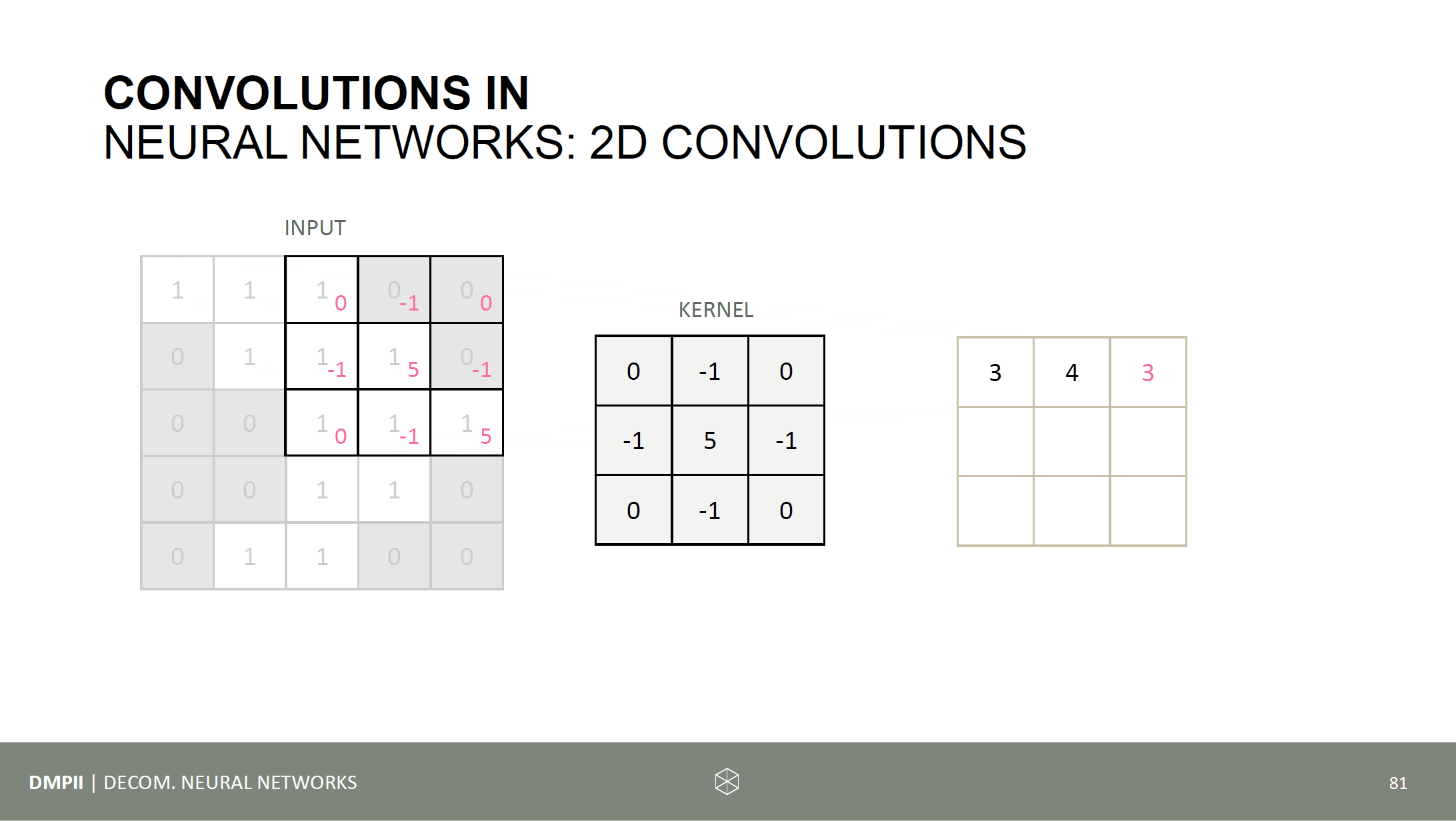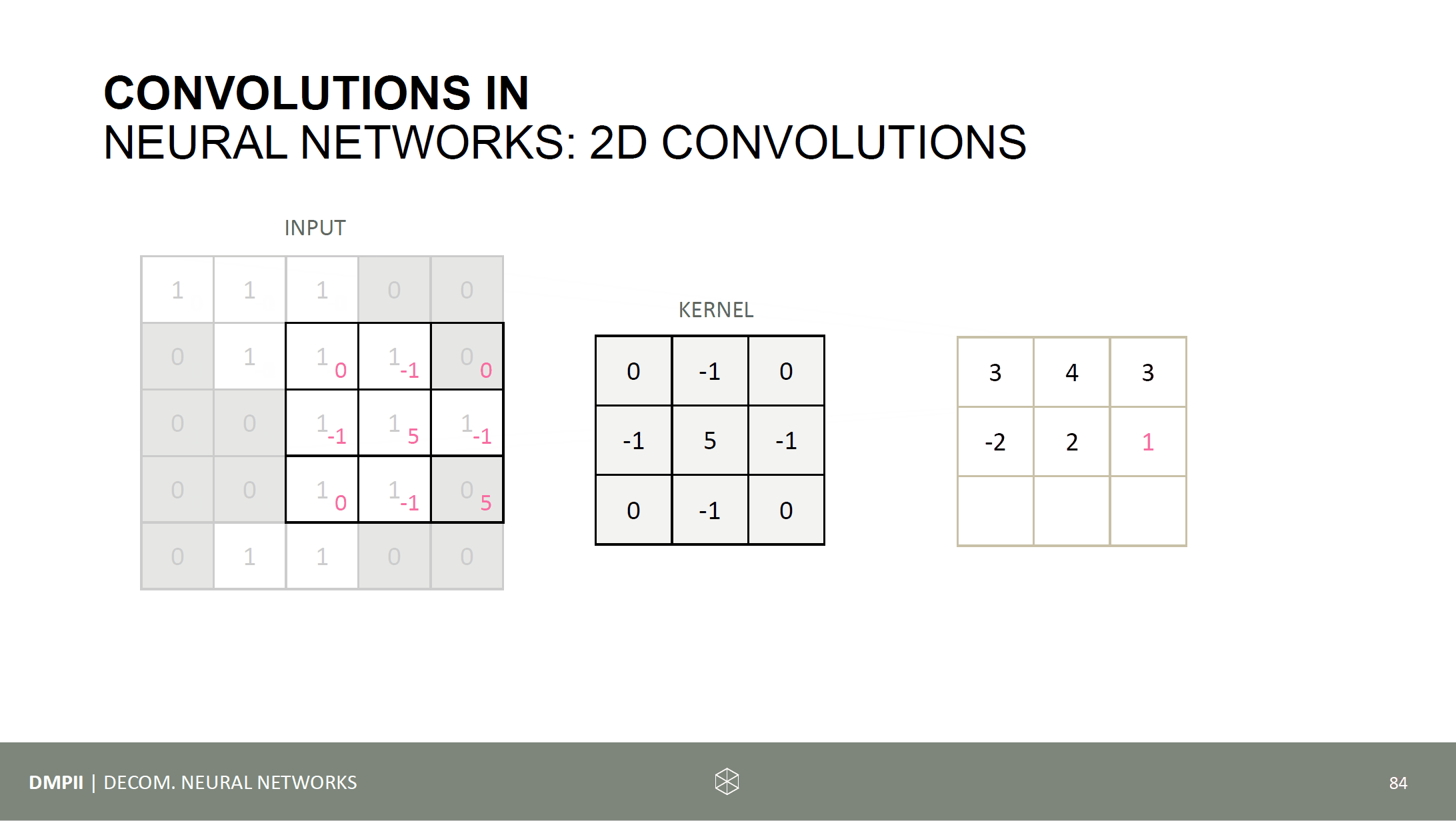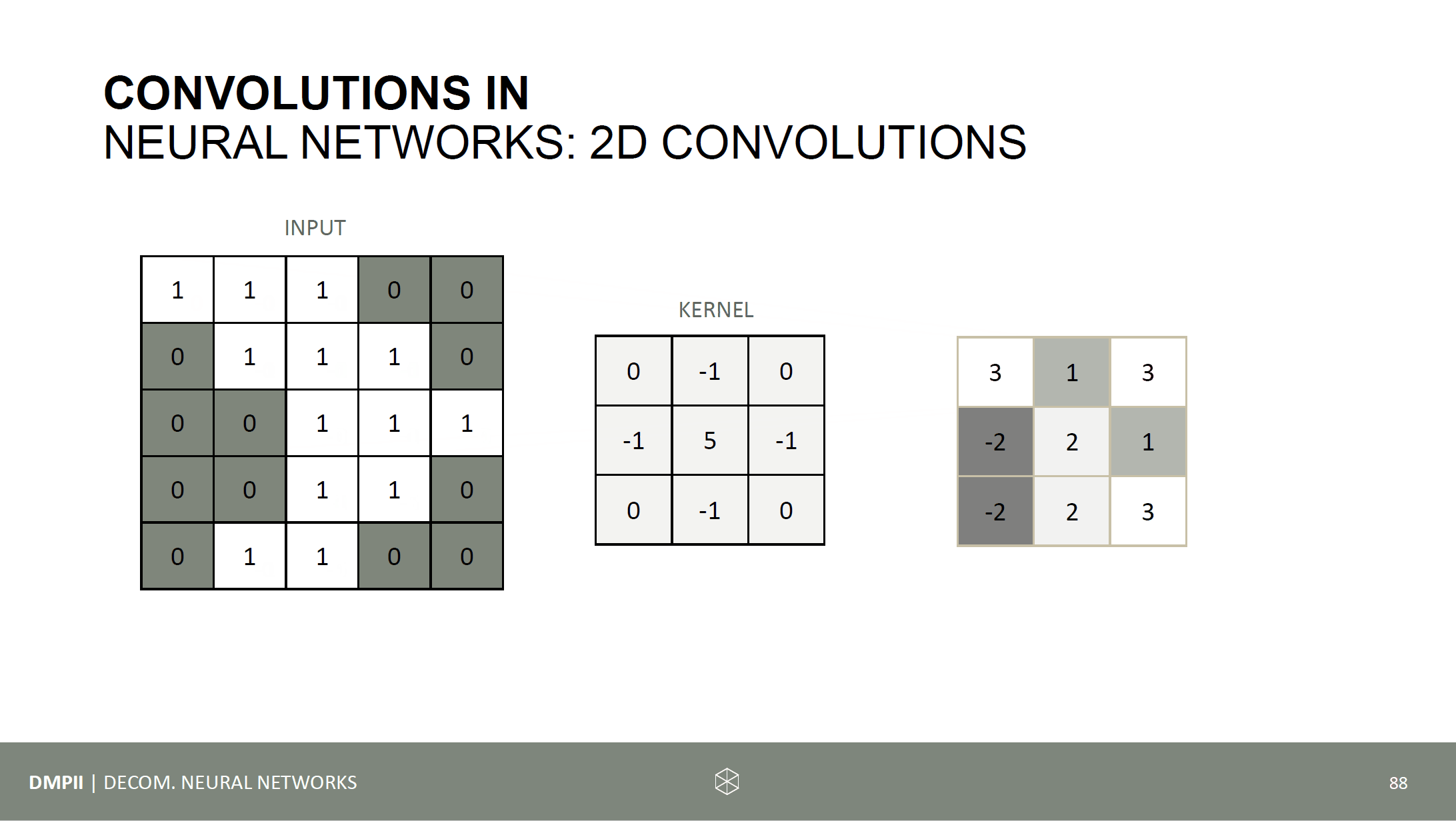
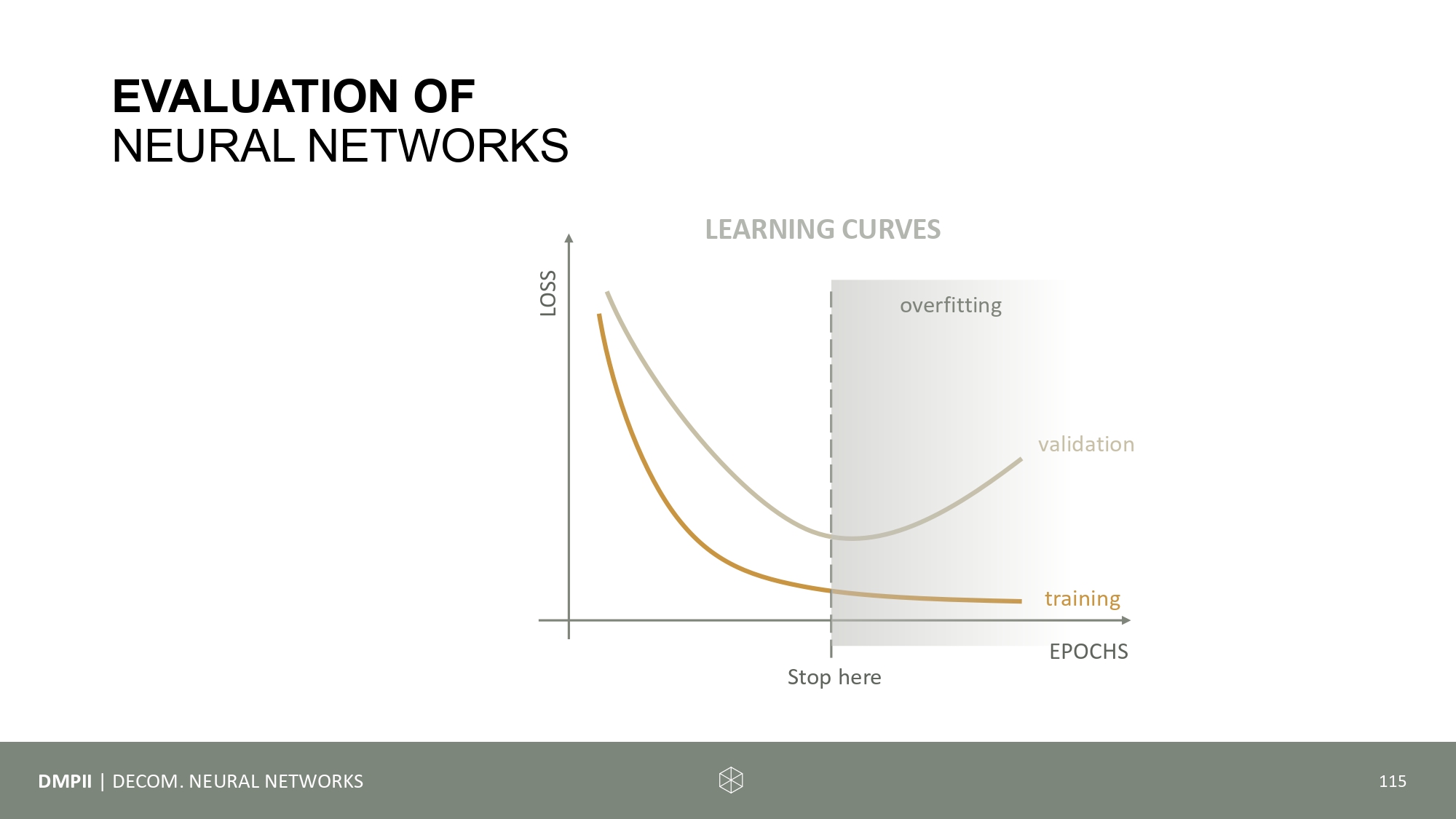

Time to run some code experiments. The following things should be investigated:
- Transforms: In line 12 of train.py we have to declare a transform option that will be applied to the images. In the glob.py are various transform compositions. Some use normalisation or rotation and flipping, while others don't. What happens with the performance, when you use another transform option? I recommend using the same transform for training and testing (but feel free to investigate the impact).
-
Pretraining: In line 16 of train.py, we load an existing model. Pretraining is set to true, meaning the weights and biases are already adjusted for image classification.
In the default experiment, we just want to "fine-tune" it, by retraining just a few layers.
What happens with the performance, when we set
pretrained=False
? Remember, when we do not load a pre-trained model we do not want to freeze layers, since they have not been adjusted yet. We need to comment out lines 20-24.
For each change, we have to run the training.py to get a model and then run the test.py. Remember to adapt the name:
- in training.py line 34 (this is where you set the name for saving the model) and
- in test.py, to call the model by name which you want to test.
It helps having every hyperparameter set up in the name of the model. In this way, you know under which conditions I trained the model. The Results of the testing will be automatically saved in separate files (see lines 45-47 in test.py). If you use a different transform, make sure that you note this is the text, which is saved in the result file (line 47 in test.py).
Train & test at least 4 different models.
- reduce the number of epochs, since it might take quite long. How long is required to be "good" on the validation set
- What happens if one model is tested twice but using different transformations?
- What is if we train with even fewer data/ selected data? You might want to experiment with moving the images in the training folder to make such a selection.